
Mplus数据分析:潜在类别分析(LCA)流程(详细版
终于开始整理这部分内容了。
关于LCA的R语言做法介绍可以看另一篇文章:R数据分析:用R语言做潜类别分析LCA
Step1: 数据准备
数据文件应包括以下变量:ID、进行分类的维度。后续分析需要的变量,如协变量(预测变量和结果变量)。注:缺失值替换成999;数据文件保存成csv格式。
格式保存:在spss软件里处理好数据,另存为csv格式即可,保证csv文件没有中文,只能是数值形式。数据文件包括的变量看图一。
ID:就是······,有多少个被试就有多少个ID。
分类的维度:指的是你的分类根据哪些条目来确定,LCA只做分类变量。打个比方,心理素质由认知品质、个性品质和适应品质三个维度构成。
协变量:可以是预测变量也可以是结局变量。预测变量(原因变量)是指其对分类有什么影响,比如用家庭社会经济地位来预测青少年欺负行为分类特征。结局变量是指青少年欺负行为特征会产生什么样的结果,比如青少年欺负行为预测抑郁症风险。
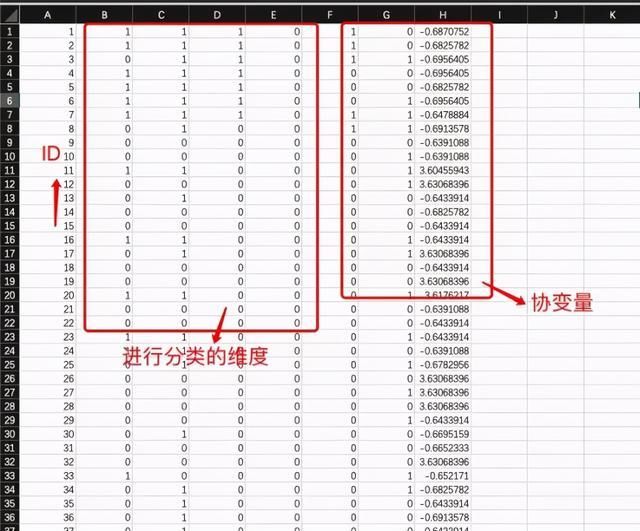
图一
Step2: Mplus分析
抽取1—6个潜在类别模型:一开始我们并不知道它会分成几类,所以一般要运行6次,然后看统计指标决定自己要分成几类。CLASSES = c(1),括号的数值就是告诉mplus你要分成几类,1就是1,2就是2,以此类推。
注:初步分析时不用Savedata语句。运行不同的模型时只需改动“CLASSES = c(1)”中的1。
代码解释看图二。
写好命令之后,点击run就好了。
analysis那部分,不变就好了。具体解释是啥我就不说了。plot也是。
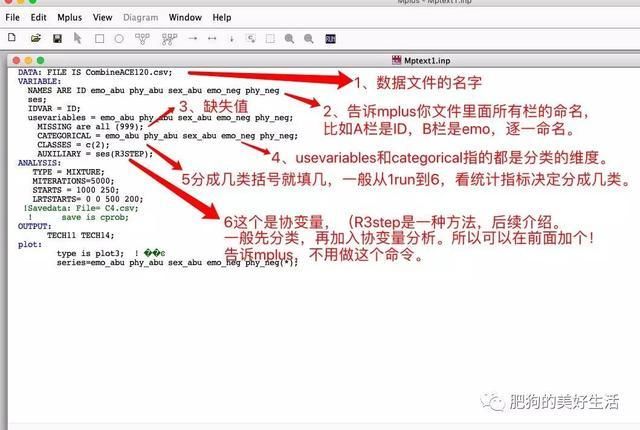
图二
Step3: 拟合指标结果整理(见图三)
统计AIC、BIC、aBIC、Entropy、LMR(p)、BLRT(p)指标。前3个数值越小表示模型拟合得越好,Entropy 指数取值范围0~1,越接近1,模型分类越准确。当 Entropy=0.6时,表明约有20%的个体存在分类的错误,Entropy约等于0.8时表明分类的准确率超过了90%。LMR和 BLRT两个指标的p值达到显著水平,则表明k个类别的模型显著优于k-1个类别的模型。
注:
BLRT: PARAMETRIC BOOTSTRAPPED LIKELIHOODRATIO TEST FOR 1 (H0) VERSUS 2 CLASSES
LMR: VUONG-LO-MENDELL-RUBIN LIKELIHOOD RATIOTEST FOR 1 (H0) VERSUS 2 CLASSES
Step4: 比较各类模型下的潜在类别在维度上的条件概率(分类的理论解释)
①统计各类别概率(FINALCLASS COUNTS AND PROPORTIONS FOR THE LATENT CLASSES BASED ON THE ESTIMATED MODEL)
②特征比较:画图看各类别的特征。各类别有哪些相同的类和不同的类?多出的类是否可解释,类别概率是否足够大?模型是否简约?与划界分对比。

图三
具体图三的指标根据分析结果找。如下图
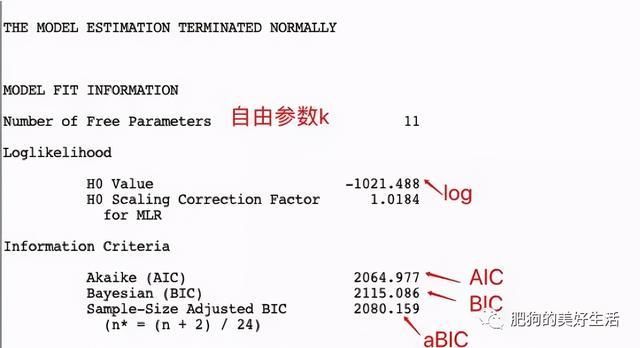




根据以上统计指标,我们可以确定分类几类。
然后需要把每一个类在每个维度的得分(或者说是概率)统计。像图四那样,然后根据图四,在Excel表格作图,如图五。
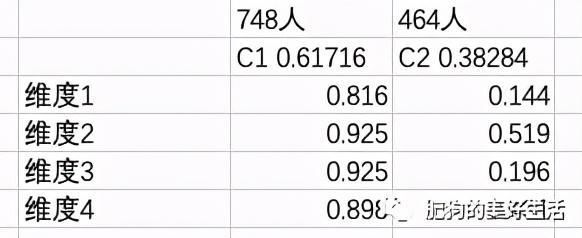
图四
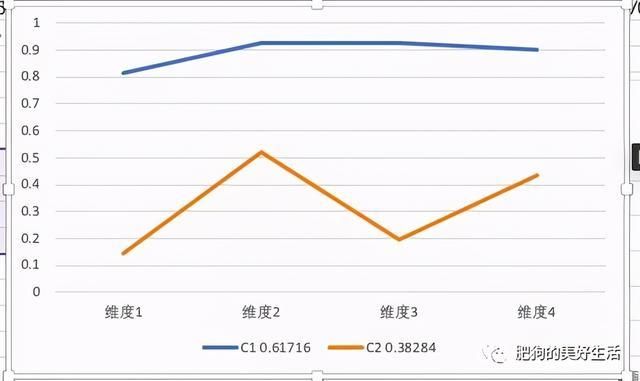
图五
那么这些统计数值哪里来的呢?看图七
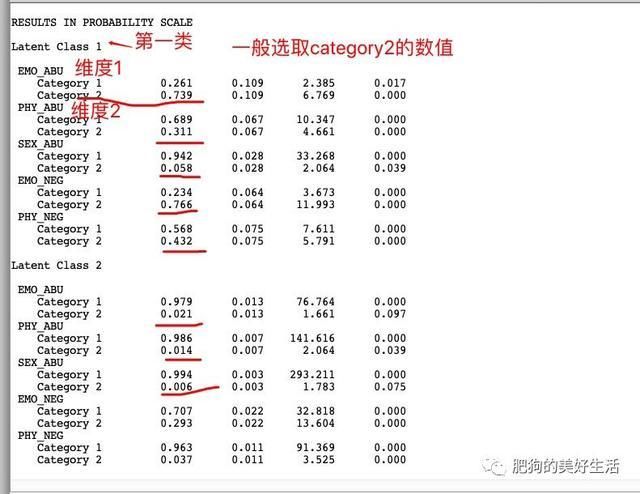
图七
然后完成啦!
在论文当中一般呈现图三、图六和类别概率图(下图,我在别的论文截图的)来说明你是怎么确定分类的。
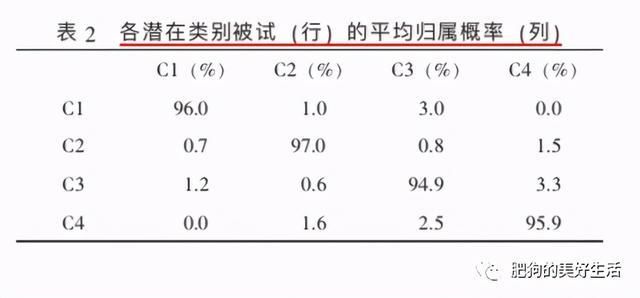
图八
Step5: 确定类别模型,命名各类别。
根据上述模型拟合指标及分类的理论解释,确定最优模型,并对各类别进行命名。
Step6: 保存归属概率及归属类别(可选)