
机器学习算法中分类知识总结!

转自丨?公众号Datawhale
作者丨张峰
本文将介绍机器学习算法中非常重要的知识—分类(classification),即找一个函数判断输入数据所属的类别,可以是二类别问题(是/不是),也可以是多类别问题(在多个类别中判断输入数据具体属于哪一个类别)。与回归问题(regression)相比,分类问题的输出不再是连续值,而是离散值,用来指定其属于哪个类别。分类问题在现实中应用非常广泛,比如垃圾邮件识别,手写数字识别,人脸识别,语音识别等。
逻辑回归返回的是概率。你可以“原样”使用返回的概率(例如,用户点击此广告的概率为 0.00023),也可以将返回的概率转换成二元值(例如,这封电子邮件是垃圾邮件)。
如果某个逻辑回归模型对某封电子邮件进行预测时返回的概率为 0.9995,则表示该模型预测这封邮件非常可能是垃圾邮件。相反,在同一个逻辑回归模型中预测分数为 0.0003 的另一封电子邮件很可能不是垃圾邮件。可如果某封电子邮件的预测分数为 0.6 呢?为了将逻辑回归值映射到二元类别,你必须指定分类阈值(也称为判定阈值)。如果值高于该阈值,则表示“垃圾邮件”;如果值低于该阈值,则表示“非垃圾邮件”。人们往往会认为分类阈值应始终为 0.5,但阈值取决于具体问题,因此你必须对其进行调整。
我们将在后面的部分中详细介绍可用于对分类模型的预测进行评估的指标,以及更改分类阈值对这些预测的影响。
?? 注意:
“调整”逻辑回归的阈值不同于调整学习速率等超参数。在选择阈值时,需要评估你将因犯错而承担多大的后果。例如,将非垃圾邮件误标记为垃圾邮件会非常糟糕。不过,虽然将垃圾邮件误标记为非垃圾邮件会令人不快,但应该不会让你丢掉工作。
在本部分,我们将定义用于评估分类模型指标的主要组成部分先。不妨,我们从一则寓言故事开始:
伊索寓言:狼来了(精简版) 有一位牧童要照看镇上的羊群,但是他开始厌烦这份工作。为了找点乐子,他大喊道:“狼来了!”其实根本一头狼也没有出现。村民们迅速跑来保护羊群,但他们发现这个牧童是在开玩笑后非常生气。(这样的情形重复出现了很多次。)
...
一天晚上,牧童看到真的有一头狼靠近羊群,他大声喊道:“狼来了!”村民们不想再被他捉弄,都待在家里不出来。这头饥饿的狼对羊群大开杀戒,美美饱餐了一顿。这下子,整个镇子都揭不开锅了。恐慌也随之而来。
我们做出以下定义:
“狼来了”是正类别。
“没有狼”是负类别。
我们可以使用一个 2x2的混淆矩阵来总结我们的“狼预测”模型,该矩阵描述了所有可能出现的结果(共四种):
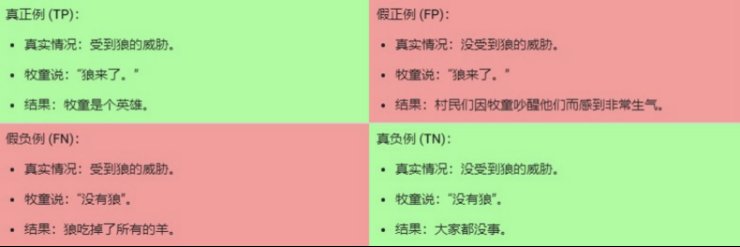
真正例是指模型将正类别样本正确地预测为正类别。同样,真负例是指模型将负类别样本正确地预测为负类别。
假正例是指模型将负类别样本错误地预测为正类别,而假负例是指模型将正类别样本错误地预测为负类别。
在后面的部分中,我们将介绍如何使用从这四种结果中衍生出的指标来评估分类模型。
准确率是一个用于评估分类模型的指标。通俗来说,准确率是指我们的模型预测正确的结果所占的比例。正式点说,准确率的定义如下:

对于二元分类,也可以根据正类别和负类别按如下方式计算准确率:
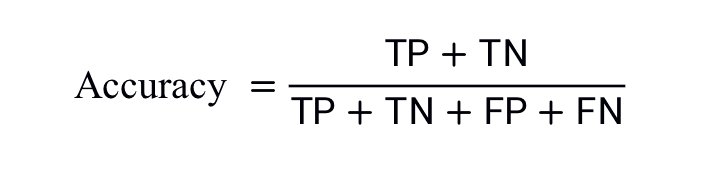
其中,TP = 真正例,TN = 真负例,FP = 假正例,FN = 假负例。让我们来试着计算一下以下模型的准确率,该模型将 100 个肿瘤分为恶性 (正类别)或良性(负类别):
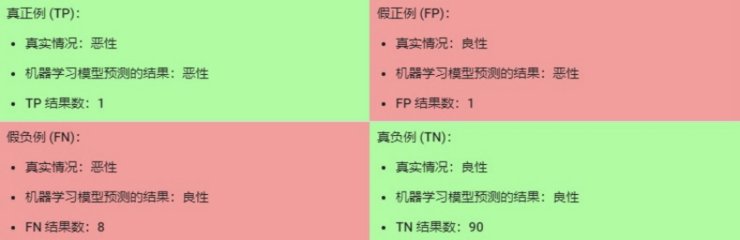

准确率为 0.91,即 91%(总共 100 个样本中有 91 个预测正确)。这表示我们的肿瘤分类器在识别恶性肿瘤方面表现得非常出色,对吧?
实际上,只要我们仔细分析一下正类别和负类别,就可以更好地了解我们模型的效果。
在 100 个肿瘤样本中,91 个为良性(90 个 TN 和 1 个 FP),9 个为恶性(1 个 TP 和 8 个 FN)。